
分布式是大型网站的必经之路,也是架构师的必备技能,掌握好分布式非常重要,下面我就全面来详解分布式@mikechen
分布式服务
分布式服务是将应用程序功能拆分成独立的服务,每个服务可以独立开发、部署、和管理。
最典型的,就是“微服务架构”,如下图所示:

将应用,拆分成多个细粒度的服务,每个服务负责特定业务功能,比如:用户服务、商品服务、订单服务…等等。
如下图所示:

每个微服务都是独立开发、部署,每个服务,通过轻量级通信机制(如:HTTP、gRPC)进行交互。
负载均衡
在分布式系统中,“负载均衡”在分布式集群中是一个关键组件,将客户端的请求分发到多个服务器节点上。
如下图所示:

负载均衡的核心:是将传入的请求、或流量,根据一定的策略分配到不同的服务器节点。
比如:通过Nginx负载,根据”常见的策略“,把流量分发到多台“tomcat服务器“,这样就把压力转移到集群来分担压力。
常见的策略,包含:
- 轮询(Round Robin):按顺序,将请求分发到各个服务器,适用于节点性能相近的情况;
- 加权轮询(Weighted Round Robin):根据服务器的不同权重进行分发,权重高的服务器分配到更多的请求;
- 最小连接数(Least Connections):将请求分发到当前连接数最少的服务器,适用于长连接服务;
- 加权最小连接数(Weighted Least Connections):结合服务器权重、和当前连接数进行分发;
- IP哈希(IP Hash):根据请求的IP地址进行哈希运算,将同一IP的请求分配到固定的服务器,适用于需要会话保持的情况;
- 随机(Random):随机选择一台服务器进行请求分发,适用于简单场景;
- 响应时间(Response Time):将请求分配到响应时间最短的服务器,适用于需要快速响应的应用。
通过负载均衡,从而优化资源利用率、最大化吞吐量、减少响应时间,并避免单点故障。
分布式缓存
分布式缓存是一种用于提升系统性能和扩展性的技术,通过在多台机器上共享缓存数据,能够快速访问频繁使用的数据,减少数据库查询压力,提高系统响应速度。
分布式缓存通过缓存频繁访问的数据,减少数据库查询次数,从而显著提升系统的读写性能。
主流的分布式缓存技术:Redis、Memcached…等。
Redis内存存储和持久化支持,支持多种数据结构如:字符串、哈希、列表、集合等。

这也正式为什么很多人选择Redis的原因,因为能支持的数据结构比较多。
除此之外,Redis还支持主从复制、和集群模式,通过分片来扩展,这在分布式缓存也是非常重要的。
分布式缓存在以下场景中应用广泛:
- Web应用:缓存用户会话数据、热点数据、和静态内容,提高页面加载速度和用户体验;
- 电商平台:缓存商品信息、库存状态和用户购物车数据,减少数据库访问压力,提升系统响应速度;
- 社交网络:缓存用户信息、好友列表、和动态数据…等,快速响应用户请求;
- 图片等:分布式缓存用来缓存静态内容,如图片、视频等,减轻源站服务器负载,提升内容分发效率。
分布式锁
在单机环境中,多线程的资源竞争,可以通过 synchronized 、和 ReentrantLock 来解决。
如下图所示:

由于是在同一个JVM里,可以有效地避免多线程并发访问共享资源导致的数据不一致、和竞态条件问题。
但是,在分布式系统中,传统的单机并发控制机制如 :synchronized 和 ReentrantLock 由于各个节点之间无法直接共享锁状态,因此失效、或无法直接使用。
所以,这时候就需要使用分布式锁,来确保全局唯一的锁定状态。

在分布式系统中,实现分布式锁需要解决以下核心问题:
- 锁的唯一性:多个节点之间,必须保证同一时刻只有一个节点可以持有锁;
- 可靠性:即使在节点故障、或网络分区的情况下,也能正确地处理锁的获取、和释放;
- 性能:需要考虑分布式锁的性能开销,避免成为系统的瓶颈。
在分布式系统中,Redis 是一种常用的实现分布式锁的实现。
在 Redis 中使用 SETNX 命令来尝试获取锁:
SETNX lock_key unique_value
lock_key是用来表示锁的键名。unique_value是一个唯一的标识,可以是请求的唯一ID或者随机生成的唯一字符串,用来区分不同的请求或客户端。
如果 SETNX 返回 1,表示成功获取锁;返回 0,表示锁已经被其他客户端持有,获取失败。
在实际应用中,需要考虑锁的超时设置、异常处理以及锁释放的正确性,以保证系统的稳定性和可靠性。
分布式事务
分布式事务(Distributed Transaction),是指涉及多个独立的数据、库或服务的事务操作。
确保这些操作要么全部成功,要么全部失败,以保证数据一致性和完整性。
如下图所示:

为了解决分布式事务的问题,通常采用以下几种实现方式:
1、两阶段提交(Two-Phase Commit, 2PC)
主要涉及:两阶段:
第一阶段:准备阶段
事务协调器(Transaction Coordinator),向所有参与者发出准备请求,每个参与者根据请求准备事务并记录预提交状态。
如果所有参与者都成功,则进入下一阶段,如果有任何一个参与者失败或超时,则中止事务。
第二阶段:提交阶段
如果准备阶段成功,事务协调器向所有参与者发送提交请求,参与者提交事务并释放资源。
如果有任何一个参与者无法提交,则所有参与者,都将回滚事务。
两阶段提交保证了事务的原子性和一致性,但存在阻塞问题(参与者在准备阶段可能会长时间阻塞)、和单点故障(协调器故障可能导致整个系统无法工作)。
2、补偿事务(Compensating Transaction)
当两阶段提交不适用、或者不合适时,可以采用补偿事务的方式。
即在主事务执行后,执行一个补偿操作来回滚、或者修正之前的操作。
这种方式需要应用程序设计支持,并且需要特别注意补偿操作的正确性、和幂等性。
3、消息队列实现最终一致性:
对于不需要强一致性的场景,可以使用消息队列:实现最终一致性。
例如:将事务中的操作转换为消息发布,由消费者异步处理。
即使在消息队列中出现部分故障,也可以通过重试机制、或者定期扫描,来确保最终一致性。
分布式文件
分布式文件系统”是一种能够管理、和存储文件的系统,其数据跨越多个物理、或虚拟节点进行分布存储。
比如:Apache Hadoop 分布式文件系统,用于存储大数据,以及GFS(Google开发的)…等。
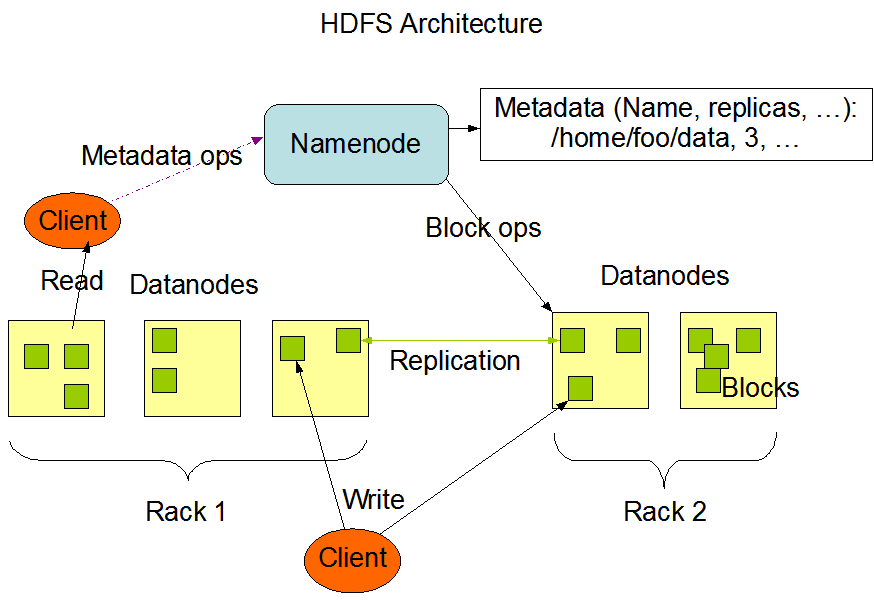
文件被分割、和存储在多个节点上,允许并行访问和处理,支持高并发访问和快速数据检索。
分布式ID
在分布式系统中,生成唯一标识符(ID)是非常重要的需求,常见的应用包括:订单号生成、消息队列 ID、数据库主键…等。
雪花算法(Snowflake) 算法,目前是应用最广泛的。
雪花算法(Snowflake) 算法,由Twitter设计的分布式ID生成算法,可以在多台机器上生成唯一且有序的ID。
ID由64位二进制组成,其中包含:时间戳、机器ID和序列号。

分布式数据库
分布式数据库是指:数据分布在多个物理、或虚拟节点上的数据库系统,它提供了跨多个节点的数据存储、访问、和处理能力。
将数据分布在多个节点上,并通过数据分片来提高查询性能和吞吐量。
作者简介
陈睿|mikechen,10年+大厂架构经验,BAT资深面试官,就职于阿里巴巴、淘宝、百度等一线互联网大厂。
关注作者「mikechen」公众号,获取更多技术干货!

后台回复【架构】,即可获取《阿里架构师进阶专题全部合集》,后台回复【面试】即可获取《史上最全阿里Java面试题总结》