
分布式是大型网站的必经之路,也是架构师的必备技能,掌握好分布式非常重要,下面我就全面来详解分布式@mikechen
分布式
分布式是一种计算机系统架构,其中系统中的组件分布在网络上的多个节点上。
这些节点可以是物理的服务器、或者容器,通过将系统的不同部分分散在多个节点上,以提高系统的性能、可伸缩性。

分布式架构
分布式架构是分布式的具体实现,包括:微服务架构、分布式缓存、分布式事务、分布式存储系统等等,下面我就一一来详解@mikechen。
微服务架构
微服务架构是一种软件设计模式,将一个应用程序拆分为一组小型、独立的服务。
如下图所示:
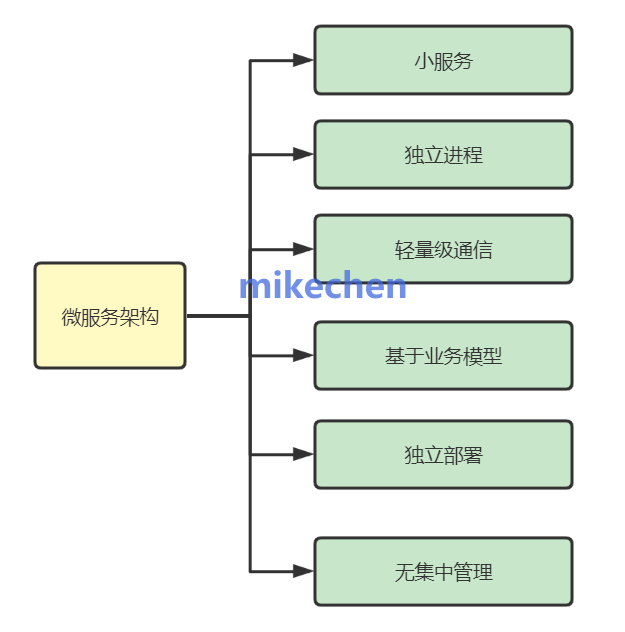
主要包含,如下特点:
- 分布式: 微服务被设计为独立运行在不同的进程或容器中,可以分布在不同的服务器上。
- 独立性: 每个微服务都是独立开发、部署和运行的单元,这种独立性使得团队可以独立地开发和部署各自的服务。
- 自治性: 微服务是自治的,即每个服务负责自己的业务逻辑和数据存储,它们可以独立进行升级、扩展和故障恢复。
- 弹性: 微服务架构是弹性的,可以根据负载的变化动态地伸缩,这使得系统更容易适应不同的工作负载和流量。
目前国内企业使用的微服务架构主要是:SpringCloud、SpringCloudAlibaba、ServiceMesh服务网格。
1.SpringCloud
Spring Cloud 提供了一系列的子项目,每个子项目都专注于解决分布式系统中的某个具体问题。
如下图所示:

SpringCloud主要包括了常用的组件和子项目:
- Eureka:提供了服务注册与发现的能力,使得微服务可以动态地注册和发现彼此。
- Ribbon:为客户端提供了负载均衡和容错能力,使得客户端请求可以分发到多个服务实例中。
- Hystrix:实现了断路器模式,可以防止分布式系统中的级联故障,提高系统的容错性和稳定性。
- Zuul:提供了 API 网关服务,用于统一管理和路由微服务的请求,同时也支持过滤器等功能。
- Spring Cloud Config:用于集中管理分布式系统的配置,支持 Git、SVN 等多种配置源。
- OpenFeign:基于注解和模板的 HTTP 客户端,简化了服务之间的调用,并与 Ribbon 结合实现了负载均衡。
- Spring Cloud Sleuth:提供了分布式跟踪和日志收集的功能,用于追踪和监控分布式系统中的请求。
这些组件和子项目构成了 Spring Cloud 的核心体系,为构建和管理分布式系统提供了丰富的功能和解决方案。
2.SpringCloudAlibaba
Spring Cloud Alibaba 是 Spring Cloud 的一个子项目,它基于阿里巴巴的开源框架,提供了一套完整的微服务架构解决方案。
Spring Cloud Alibaba 的主要组件,如下图所示:

1.Nacos
Nacos 提供了服务注册与发现、动态配置管理、服务健康监测等功能。
2.Sentinel
Sentinel ,一个轻量级的流量控制和并发限制库。
3.Dubbo
Dubbo,一个高性能的分布式服务框架,支持面向接口的远程方法调用,以及服务注册、发现和治理。
4.RocketMQ
RocketMQ,是一个分布式消息中间件,提供了高可靠性、高吞吐量的消息传递服务。
5.Seata
Seata 提供了高性能的分布式事务服务,可以与 Spring Cloud Alibaba 无缝集成。
这些组件涵盖了微服务架构中的服务注册与发现、配置管理、流量控制、熔断降级、消息中间件、分布式事务等关键领域。
3.ServiceMesh
Service Mesh服务网格,是新一代的微服务框架。
Sservice Mesh是一个形象化的词语表达:Service(服务)和Mesh(网格)。
如下图所示:

Service Mesh 使用 sidecar 模型,即在每个服务实例旁边运行一个轻量级代理。
Sidecar 是运行在每个微服务实例旁边的代理,负责处理与该服务实例相关的通信、安全性、负载均衡等任务。
Sidecar 模型的引入使得 Service Mesh 可以在不修改应用程序代码的情况下,实现对微服务间通信的细粒度控制和管理。

Istio 和 Linkerd 是两个常见的 Service Mesh 实现,它们提供了 Service Mesh 的核心功能,并与多种微服务框架和编程语言兼容。
负载均衡
在分布式系统、网络系统和服务架构中,负载均衡起着关键的作用。
负载均衡是一种将工作负载,比如:请求、数据流量等,分布到多个服务器上。
如下图所示:

通过平衡工作负载,负载均衡可以提高系统的性能、可扩展性和稳定性。
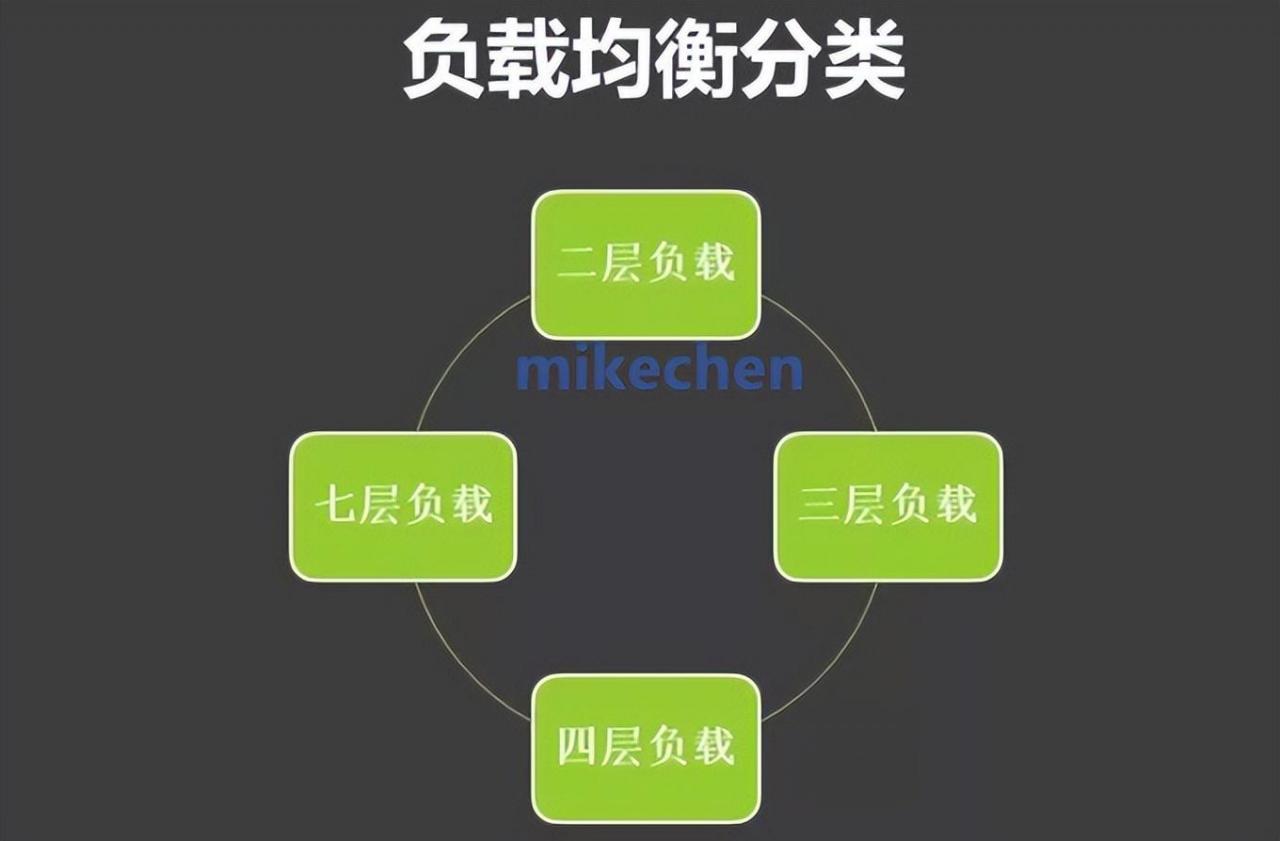
二层负载均衡(Layer 2 LB):
- 位置: 在数据链路层(二层)进行负载均衡。
- 特点: 主要通过MAC地址进行负载均衡,不涉及IP地址或端口。
- 适用场景: 常用于在同一子网内的服务器负载均衡,例如交换机层面的负载均衡。
三层负载均衡(Layer 3 LB):
- 位置: 在网络层(三层)进行负载均衡,基于IP地址和端口进行。
- 特点: 负载均衡设备根据IP地址和端口信息将流量分发到后端服务器。
- 适用场景: 通常用于在不同子网之间进行负载均衡,可以根据网络路由表进行流量分发。
四层负载均衡(Layer 4 LB):
- 位置: 在传输层(四层)进行负载均衡,基于IP地址、端口号和传输层协议(如TCP、UDP)。
- 特点: 负载均衡设备根据传输层信息将流量分发到后端服务器,不涉及应用层信息。
- 适用场景: 常用于负载均衡TCP和UDP流量,适用于大多数应用场景。
七层负载均衡(Layer 7 LB):
- 位置: 在应用层(七层)进行负载均衡,基于应用层协议(如HTTP、HTTPS)进行。
- 特点: 负载均衡设备能够深度理解应用层协议,根据请求内容、URL等信息进行智能分发。
- 适用场景: 适用于需要根据应用层信息进行精细的负载均衡,如Web应用负载均衡、HTTPS负载均衡等。
总之,较低层次的负载均衡通常更快速,但提供的分发决策相对简单。
较高层次的负载均衡能够实现更精细的分发策略,但可能带来更大的性能开销。
常见的负载均衡软件:
1.Nginx
Nginx 提供四层(TCP和UDP)和七层(HTTP和HTTPS)的负载均衡。
2.HAProxy
HAProxy 主要用于四层负载均衡(TCP和UDP),但也可以用于七层负载均衡。
3.F5
F5 BIG-IP 提供七层(应用层)的负载均衡,支持 HTTP、HTTPS 等协议。
负载均衡策略:
- 轮询负载均衡: 将请求轮流分发到多个服务器,确保每个服务器都有机会处理请求。
- 基于权重的负载均衡: 根据服务器的性能或配置不同分配不同的权重,使性能更好的服务器能够处理更多的请求。
- 哈希算法负载均衡: 使用哈希函数将请求映射到特定的服务器,确保相同的请求始终被发送到相同的服务器。
- 最小连接数负载均衡: 将请求分发到当前连接数最少的服务器,确保负载更均匀。
分布式缓存
分布式缓存使得数据可以被快速检索和访问,从而减轻了数据库的压力。
分布式缓存系统通常由多个缓存节点组成,这些节点可以分布在不同的服务器上。
分布式缓存系统通常通过一致性哈希等算法来保持数据一致性,确保相同的数据被缓存在相同的节点上。
常见的分布式缓存系统:
1.Redis
一个高性能的开源键值对存储系统,支持丰富的数据结构。
如下图所示:

Redis支持多种类型的数据结构,包含:字符、列表、Hash等等,这也是很多选择Redis的重要原因。
2.Memcached

一个高性能的分布式内存对象缓存系统,以键值对方式存储数据。
分布式缓存面临的难题:
1.缓存穿透
缓存穿透是指请求的数据在缓存中不存在,导致每次请求都需要查询数据库,增加了数据库的负载。
攻击者可以通过恶意请求不存在的数据来引发缓存穿透。
为了解决这个问题,可以采用布隆过滤器(Bloom Filter)等手段进行缓存失效前的数据过滤。
2.缓存雪崩
缓存雪崩是指在缓存大面积失效或者某个节点宕机的情况下,大量请求直接访问数据库,导致数据库系统崩溃。
为了防止缓存雪崩,可以采用设置不同的失效时间、使用熔断器等手段,保证缓存失效时不会同时对数据库产生过大的负载。
3.缓存一致
由于数据可能存在于多个缓存节点上,当更新数据时,需要确保所有相关节点都能够获取到最新的数据。
一致性问题涉及到:缓存的更新、失效、刷新等方面的问题。
分布式事务
事务是一组操作,要么全部成功执行,要么全部回滚。
而分布式事务是指在分布式系统中执行的事务,保证多个独立的节点资源,要么全部成功执行,要么全部回滚。
如下图所示:
在分布式系统中,事务可以涉及多个节点上的操作,这些操作必须以一致的方式提交或回滚。
分布式事务的挑战:
- 网络延迟和故障: 分布式环境中存在网络延迟和节点故障的风险,这可能导致事务协调的复杂性。
- 并发控制: 多个节点同时执行事务可能导致并发控制的问题,如脏读、不可重复读等。
- 一致性问题: 由于数据分布在多个节点上,确保全局一致性变得更为复杂。
常见的解决方案:
- 两阶段提交协议(Two-Phase Commit, 2PC): 分为投票和提交两个阶段,确保所有节点同意或回滚。
- 三阶段提交协议(Three-Phase Commit, 3PC): 在2PC的基础上引入超时机制,减少某些情况下的阻塞问题。
分布式存储系统
常见的分布式文件系统包括:HDFS、Ceph、GlusterFS、FastDFS等。
1.HDFS
HDFS是Apache Hadoop项目的一部分,主要设计用于存储和处理大规模的数据集。
它采用分布式存储和计算的架构,数据被划分成块并分布在多个节点上。
如下图所示:

适用于大规模数据的批量处理,特别是在Hadoop生态系统中用于分布式计算。
2.Ceph
Ceph是一个面向对象的分布式存储系统,它提供了对象存储、块存储和文件存储的功能。
Ceph架构,如下图所示:

Ceph采用弹性伸缩的架构,适用于需要面向对象存储、块存储和文件存储的场景。
3.GlusterFS
GlusterFS是一个开源的分布式文件系统,它通过将存储服务器聚集成一个整体来提供可扩展的存储。

适用于需要文件存储并希望在不同存储服务器之间进行弹性伸缩的场景,特别是用于容器化环境的存储解决方案。
分布式计算
分布式计算在处理大规模数据、高性能计算、机器学习等领域发挥着重要作用。
这种计算模型允许将大规模的计算任务分解为多个小的子任务,并在分布式环境中同时执行这些子任务,从而提高整体的计算能力。
以下是一些常见的分布式计算产品:
1.Apache Spark
Spark是一个通用的分布式计算框架,提供了比MapReduce更灵活、更高效的计算模型。
适用于批处理、流处理、机器学习等各种计算任务,特别是需要迭代计算的场景。
2.Apache Flink
Flink是一个分布式流处理框架,具有低延迟和高吞吐量的特点,它支持事件时间处理、窗口操作等丰富的流处理功能。
适用于实时流处理任务,特别是对事件时间敏感的应用场景。
3.Hadoop MapReduce
Hadoop是Apache开源项目的一部分,其中最著名的组件之一是MapReduce。
适用于批处理任务,特别是对大规模数据进行分布式计算和处理。
4.Apache Storm
Apache Storm 是一个开源的实时流式计算系统,用于处理大规模实时数据流。
Apache Storm 用于构建具有低延迟和高可用性要求的实时数据处理应用程序,比如:实时分析、事件处理、实时监控等。
5.Amazon EC2
亚马逊云计算服务中的一种,适用于大规模计算和分析任务。
总体而言,分布式系统设计需要综合考虑性能、可用性、一致性和容错性等多个方面的因素。
作者简介
陈睿|mikechen,10年+大厂架构经验,BAT资深面试官,就职于阿里巴巴、淘宝、百度等一线互联网大厂。
关注作者「mikechen」公众号,获取更多技术干货!

后台回复【架构】,即可获取《阿里架构师进阶专题全部合集》,后台回复【面试】即可获取《史上最全阿里Java面试题总结》
感谢分享